使用python批量处理工作簿和工作表 |
您所在的位置:网站首页 › xlwings 关闭工作簿且不保存 › 使用python批量处理工作簿和工作表 |
使用python批量处理工作簿和工作表
|
案例01 批量新建并保存工作簿
将for语句与xlwings模块相结合,就可以轻松实现批量创建工作簿 import xlwings as xw # 导入xlwings模块 app = xw.App(visible=True,add_book=False) # 启动Excel程序,但不新建工作簿 for i in range(6): workbook = app.books.add() # 新建工作簿 workbook.save(f'D:\\file\\test{i}.xlsx') # 保存新建的多个工作簿代码解析 第一行导入xlwings模块 第二行启动Excel程序 第三行~第五行用for语句构造了一个循环来完成工作簿的批量新建和保存 第三行代码的range()函数括号内的数值6代表新建工作薄的数量,如果要新建100个工作簿,则将数值改为100。上述代码在运行时i的值会依次变为0、1、2、3、4、5。 第四行代码新建一个工作簿后,第5行代码接着在指定路径下有规律的文件名保存新建的工作簿。其中”D:\\file“是新建工作簿的保存路径,这里采用的是绝对路径,如果写成相对路径的形式”workbook.save(f'test{i}.xlsx')",则会在上述代码文件所在的文件夹下保存新建的工作簿。 “test{i}.xlsx”指定了工作簿的文件名,可以根据实际需求更改。 其中“test”和“.xlsx”是文件名中固定的部分,而“{i}”则是可变部分,运行时会被替换为i的实际值。 运行上面代码后,会在D盘下的“file”文件夹中新建6个工作簿, 文件名分别为“test0.xlsx”、“test1.xlsx”、“test2.xlsx”、“test3.xlsx”、“test4.xlsx”、“test5.xlsx”、“test6.xlsx” 知识延伸:
第5行代码在构造有规律的文件名时使用的是拼接字符串的方法。用'+"运算符来拼接字符串,这里使用的则是另一种方法——f-string方法。 该方法以f或F修饰符引领字符串,然后在字符串中以大括号{}标明被替换的内容。 使用该方法无须事先转换数据类型就能将不同类型的数据拼接成字符串。 name = '小明' age = 7 a = f'{name}今年{age}岁' print(a)运行结果
批量新建并关闭工作簿 import xlwings as xw # 导入xlwings模块 app = xw.App(visible=True,add_book=False) # 启动Excel程序,但不新建工作簿 for i in range(6): workbook = app.books.add() # 新建工作簿 workbook.save(f'D:\\file\\test{i}.xlsx') # 保存新建的多个工作簿 workbook.close() # 关闭当前工作簿 app.quit() # 退出Excel程序 案例02 批量打开一个文件下的所有工作簿——table(文件夹) import os # 导入os模块 import xlwings as xw # 导入xlwings模块 file_path = 'D:\\table' # 给出工作簿所在的文件夹路径 file_list = os.listdir(file_path) # 列出路径下所有文件和子文件夹的名称 app = xw.App(visible = True, add_book = False) # 启动Excel程序 for i in file_list: if os.path.splitext(i)[1] == '.xlsx': # 判断文件夹下的扩展名是否为'.xlsx' app.books.open(file_path + '\\' + i) # 打开工作簿如果同时要打开扩展名为“.xlsx"和".xls"的工作簿,可将第7行代码更改为“if os.path.splitext(i)[1] =='.xlsx' or os.path.splitext(i)[1] == '.xls':”。 ①第4行代码中的listdir()函数用于返回指定路径下的文件夹包含的文件和子文件夹的名称列表 ②第7行代码中的splitext()函数用于分离文件主名和扩展名。 列出文件夹下所有文件和子文件夹的名称——table(文件夹) import os file_path = 'd:\\table' file_list = os.listdir(file_path) for i in file_list: print(i) 案例03 批量重命名一个工作簿中的所有工作表——统计表.xlsx import xlwings as xw # 导入xlwings模块 app = xw.App(visible = False, add_book = False) # 启动Excel程序 workbook = app.books.open('d:\\table\\统计表.xlsx') # 打开工作簿 worksheets = workbook.sheets # 获取工作簿中的所有工作表 for i in range(len(worksheets)): # 遍历获取到的工作表 worksheets[i].name = worksheets[i].name.replace('销售', '') # 重命名工作表 workbook.save('d:\\table\\统计表1.xlsx') # 另存重命名工作表后的工作簿 app.quit() # 退出Excel程序批量重命名一个工作簿中的部分工作表——统计表.xlsx 重命名前5个工作表 import xlwings as xw app = xw.App(visible = False, add_book = False) workbook = app.books.open('d:\\table\\统计表.xlsx') worksheets = workbook.sheets for i in range(len(worksheets))[:5]: # 通过切片来选中部分工作表 worksheets[i].name = worksheets[i].name.replace('销售', '') workbook.save('d:\\table\\统计表1.xlsx') app.quit() 案例04 批量重命名多个工作簿——产品销售表批量命名多个工作簿名必须是有规律的,或者含有相同的关键字。 import os # 导入os模块 file_path = 'd:\\table\\产品销售表' # 给出待重命名工作簿所在文件夹的路径 file_list = os.listdir(file_path) # 列出文件夹下所有文件和子文件夹的名称 old_book_name = '销售表' # 给出工作簿名中需要替换的旧关键字 new_book_name = '分部产品销售表' # 给出工作簿名中要替换为新的关键字 for i in file_list: if i.startswith('~$') : # 判断是否有文件名以“~$”开头的临时文件 continue # 如果有,则跳过这种类型的文件 new_file = i.replace(old_book_name,new_book_name) # 执行查找和替换,生成新的工作簿名 old_file_path = os.path.join(file_path,i) # 构造需要重命名工作簿的完整路径 new_file_path = os.path.join(file_path,new_file) # 构造重命名后工作簿的完整路径 os.rename(old_file_path,new_file_path) # 执行重命名代码解析 第4、5行代码用于给出工作簿名中需要替换的旧关键字和替换为新的关键字。需要注意的是,这里的关键字不是工作簿名,只是工作簿名中的部分文字。 第6~12行代码用于批量重命名文件夹中的工作簿。 因为Excel会在使用过程中生成一些文件名以“~$”开头的临时文件,所以第7行代码的if语句判断是否有这种类型的文件,如果有则跳过,不做处理,继续处理其他文件。 第9~11行代码用于构造工作簿的路径字符串,第12行代码则根据构造的路径字符串真正执行重命名操作。 知识延伸 startswith()是python内置的字符串函数,用于判断字符串是否以指定的子字符串开头。如果存在参数beg和end,则在指定范围内检索,否则将在整个字符串中检索。
os.path.join()是os模块中的函数,用于把文件夹名和文件名拼接成一个完整路径
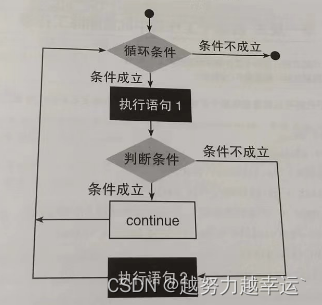
rename()是os模块中的函数,用于重命名文件和文件夹。 批量重命名多个工作簿中的同名工作表——信息表(文件夹) import os import xlwings as xw file_path = 'd:\\table\\信息表' file_list = os.listdir(file_path) old_sheet_name = 'Sheet1' # 给出需要修改的工作表名 new_sheet_name = '员工信息' #列出修改后的工作表名 app = xw.App(visible = False, add_book = False) for i in file_list: if i.startswith('~$'): continue old_file_path = os.path.join(file_path, i) workbook = app.books.open(old_file_path) for j in workbook.sheets: if j.name == old_sheet_name: # 判断工作表名是否为“Sheet1” j.name = new_sheet_name # 如果是,则重命名工作表 workbook.save() # 保存工作簿 app.quit() # 退出Excel程序 案例05 在多个工作簿中批量新增工作表——销售表(文件夹) import os # 导入os模块 import xlwings as xw # 导入xlwings模块 file_path = 'd:\\table\\销售表' # 给出要新增工作表的工作簿所在的文件夹路径 file_list = os.listdir(file_path) # 列出文件夹下所有文件和子文件夹的名称 sheet_name = '产品销售区域' # 给出要新增的工作表的名称 app = xw.App(visible=False,add_book=False) # 启动Excel程序 for i in file_list: if i.startswith('~$'): # 判断是否有文件名以“~$”开头的文件 continue # 如果有,则跳过这种类型的文件 file_paths = os.path.join(file_path, i) # 构造需要新增工作表的工作簿的文件路径 workbook = app.books.open(file_paths) # 根据路径打开需要新增工作表的工作簿 sheet_names = [j.name for j in workbook.sheets] # 获取打开的工作簿中所有工作表的名称 if sheet_name not in sheet_names: # 判断工作簿中是否不存在名为“产品销售区域”的工作表 workbook.sheets.add(sheet_name) # 如果不存在,则新增工作表”产品销售区域“ workbook.save() # 保存工作簿 app.quit() # 退出Excel程序知识延伸 continue语句通常配合if语句使用。
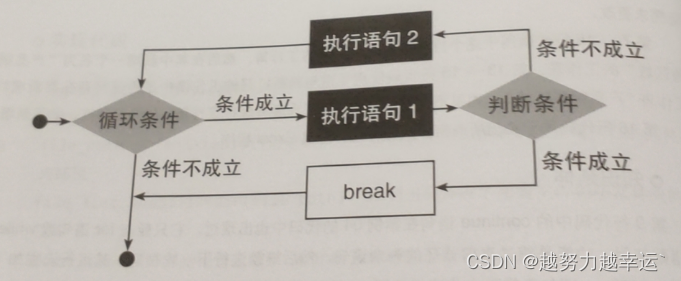
与continue语句的功能和用法类似的还有一个break语句。该语句用于终止整个循环。
在多个工作簿中批量删除工作表 —— 销售表1(文件夹) import os import xlwings as xw file_path = 'd:\\table\\销售表1' file_list = os.listdir(file_path) sheet_name = '产品销售区域' # 给出要删除的工作表的名称 app = xw.App(visible = False, add_book = False) for i in file_list: if i.startswith('~$'): continue file_paths = os.path.join(file_path, i) workbook = app.books.open(file_paths) for j in workbook.sheets: if j.name == sheet_name: # 判断工作簿中是否有名为”产品销售区域“的工作表 j.delete() # 如果有,则删除该工作表 break workbook.save() app.quit() 案例06 批量打印工作簿——公司(文件夹) import os # 导入os模块 import xlwings as xw # 导入xlwings模块 file_path = 'd:\\table\\公司' # 给出要打印的工作簿所在的文件夹路径 file_list = os.listdir(file_path) # 列出文件夹下所有文件和子文件夹的名称 app = xw.App(visible = False, add_book = False) for i in file_list: if i.startswith('~$'): continue file_paths = os.path.join(file_path, i) # 获取需要打印的工作簿的文件路径 workbook = app.books.open(file_paths) # 打开要打印的工作簿 workbook.api.PrintOut() # 打印工作簿 app.quit()知识延伸 因为xlwings模块没有提供打印工作簿的函数,所以第11行代码利用工作簿对象的api属性调用VBA的PrintOut()函数来打印工作簿。该函数的语法格式和常用参数含义如下。 PrintOut(From,To,Copies,Preview,ActivePrinter,PrintToFile,Collate,PrToFileName) 参数说明From可选参数,指定打印的开始页码。如果省略该参数,则从头开始打印To可选参数,指定打印的终止页码。如果省略该参数,则打印至最后一页Copies可选参数,指定打印份数。如果省略该参数,则只打印一份Preview可选参数,如果为True,Excel会在打印之前显示打印预览界面。如果为False或省略该参数,则会立即打印ActivePrinter可选参数,设置要使用的打印机的名称。如果省略此参数,则表示使用操作系统给默认打印机PrintToFile可选参数,如果为True,则表示不打印到打印机,而是打印成一个prn文件。如果没有指定PrToFileName,Excel将提示用户输入文件名Collate可选参数,如果为True,则逐份打印多个副本PrToFileName可选参数,如果将PrintToFile设置为True,则用该参数指定prn文件的文件名批量打印多个工作簿中的指定工作表——公司1(文件夹) import os import xlwings as xw file_path = 'd:\\table\\公司1' file_list = os.listdir(file_path) sheet_name = '产品分类表' app = xw.App(visible = False, add_book = False) for i in file_list: if i.startswith('~$'): continue file_paths = os.path.join(file_path, i) workbook = app.books.open(file_paths) for j in workbook.sheets: if j.name == sheet_name: # 判断工作簿中是否存在名为”产品分类表“的工作表 j.api.PrintOut() # 如果存在,则打印该工作表 break app.quit() 案例07 将一个工作簿的所有工作表批量复制到其他工作簿——信息表.xlsx、销售表(文件夹) import os import xlwings as xw app = xw.App(visible = False, add_book = False) file_path = 'd:\\table\\销售表' # 给出目标工作簿所在的文件夹路径 file_list = os.listdir(file_path) # 列出文件夹下所有文件和子文件夹的名称 workbook = app.books.open('e:\\table\\信息表.xlsx') # 打开来源工作簿 worksheet = workbook.sheets # 获取来源工作簿中的所有工作表 for i in file_list: if os.path.splitext(i)[1] == '.xlsx': # 判断文件是否是工作簿 workbooks = app.books.open(file_path + '\\' + i) # 如果是工作簿则将其打开 for j in worksheet: contents = j.range('A1').expand('table').value # 读取来源工作簿中要复制的工作表数据 name = j.name # 获取来源工作簿中的工作表名称 workbooks.sheets.add(name = name, after = workbooks.sheets[-1]) # 在目标工作簿中新增同名工作表 workbooks.sheets[name].range('A1').value = contents # 将从来源工作簿中读取的工作表数据写入新增工作表 workbooks.save() app.quit()知识延伸 expand()是xlwings模块中的函数,用于扩展选择范围。 语法格式: expand(mode) 参数含义: 默认值为‘table’,表示向整个数据表扩展。也可以为”down”或“right”,分别表示向表的下方和右方扩展。 将某个工作表的数据批量复制到其他工作簿的指定工作表中——新增产品表.xlsx、销售表1(文件夹) import os import xlwings as xw app = xw.App(visible = False, add_book = False) file_path = 'e:\\table\\销售表1' file_list = os.listdir(file_path) workbook = app.books.open('e:\\table\\新增产品表.xlsx') worksheet = workbook.sheets['新增产品'] # 选中工作表“新增产品” value = worksheet.range('A1').expand('table') # 选中工作表“新增产品”中已有数据的单元格区域 start_cell = (2, 1) # 给出要复制数据的单元格区域的起始单元格 end_cell = (value.shape[0], value.shape[1]) # 给出要复制数据的单元格区域的结束单元格 cell_area = worksheet.range(start_cell, end_cell).value # 根据前面设定的单元格区域选取要复制的数据 for i in file_list: if os.path.splitext(i)[1] == '.xlsx': try: workbooks = app.books.open(file_path + '\\' + i) sheet = workbooks.sheets['产品分类表'] # 选中要粘贴数据的工作表“产品分类表” scope = sheet.range('A1').expand() # 选中工作表“产品分类表”中已有数据的单元格区域 sheet.range(scope.shape[0] + 1, 1).value = cell_area # 在已有数据的单元格区域下方粘贴数据 workbooks.save() finally: workbooks.close() workbook.close() app.quit() 案例08 按条件将一个工作表拆分为多个工作簿——产品统计表 import xlwings as xw file_path = 'd:\\table\\产品统计表.xlsx' # 给出来源工作簿的文件路径 sheet_name = '统计表' # 给出要拆分的工作表的名称 app = xw.App(visible = True, add_book = False) workbook = app.books.open(file_path) # 打开来源工作簿 worksheet = workbook.sheets[sheet_name] # 选中要拆分的工作表 value = worksheet.range('A2').expand('table').value # 读取要拆分的工作表中的所有数据 data = dict() # 创建一个空字典用于按产品名称分类存放数据 for i in range(len(value)): # 按行遍历工作表数据 product_name = value[i][1] # 获取当前行的产品名称,作为数据的分类依据 if product_name not in data: # 判断字典中是否不存在当前行的产品名称 data[product_name] = [] # 如果不存在,则创建一个与当前行的产品名称对应的空列表,用于存放当前行数据 data[product_name].append(value[i]) # 将当前行的数据追加到当前行的产品名称对应的列表中 for key,value in data.items(): # 按产品名称遍历分类后的数据 new_workbook = app.books.add() # 新建目标工作簿 new_worksheet = new_workbook.sheets.add(key) # 在目标工作簿中新增工作表并命名为当前的产品名称 new_worksheet['A1'].value = worksheet['A1:H1'].value # 将要拆分的工作表的列标题复制到新建的工作表中 new_worksheet['A2'].value = value # 将当前产品名称下的数据复制到新建的工作表中 new_workbook.save('{}.xlsx'.format(key)) # 以当前产品名称作为文件名保存目标工作簿 app.quit()按条件将一个工作表拆分为多个工作表——产品统计表 import xlwings as xw import pandas as pd app = xw.App(visible = True, add_book = False) workbook = app.books.open('d:\\table\\产品统计表.xlsx') worksheet = workbook.sheets['统计表'] value = worksheet.range('A1').options(pd.DataFrame, header = 1, index = False, expand = 'table').value # 读取要拆分的工作表数据 data = value.groupby('产品名称') # 将数据按照“产品名称”分组 for idx, group in data: new_worksheet = workbook.sheets.add(idx) # 在工作簿中新增工作表并命名为当前的产品名称 new_worksheet['A1'].options(index = False).value = group # 将数据添加到新增的工作表 workbook.save() workbook.close() app.quit()将多个工作表拆分为多个工作簿——产品销售表 import xlwings as xw workbook_name = 'd:\\table\\产品销售表.xlsx' # 指定要拆分的来源工作簿 app = xw.App(visible = False, add_book = False) workbook = app.books.open(workbook_name) for i in workbook.sheets: # 遍历来源工作簿中的工作表 workbook_split = app.books.add() # 新建一个目标工作簿 sheet_split = workbook_split.sheets[0] # 选择目标工作簿中的第一个工作表 i.api.Copy(Before = sheet_split.api) # 将来源工作簿中的当前工作表复制到目标工作簿的第一个工作表之前 workbook_split.save('{}.xlsx'.format(i.name)) # 以当前工作表的名称作为文件名保存目标工作簿 app.quit() 案例09 批量合并多个工作簿中的同名工作表——销售统计(文件夹) import os import xlwings as xw file_path = 'd:\\table\\销售统计' # 给出要合并工作表的多个工作簿所在的文件夹路径 file_list = os.listdir(file_path) # 给出文件夹下所有文件和子文件夹的名称 sheet_name = '产品销售统计' # 给出要合并的同名工作表的名称 app = xw.App(visible = False, add_book = False) header = None # 定义变量header,初始值为一个空对象,后续用于存放要合并的工作表中数据的列标题 all_data = [] # 创建一个空列表 for i in file_list: if i.startswith('~$'): # 判断是否有文件名以“~$”开头的文件 continue file_paths = os.path.join(file_path, i) # 构造要合并的工作簿的文件路径 workbook = app.books.open(file_paths) # 打开要合并的工作簿 for j in workbook.sheets: if j.name == sheet_name: # 判断工作表的名称是否为“产品销售统计” if header == None: # 判断变量header中是否已经存放了列标题 header = j['A1:I1'].value # 如果未存放,则读取列标题并赋给变量header values = j['A2'].expand('table').value # 读取要合并的工作表中的数据 all_data = all_data + values # 合并多个工作簿中的同名工作表数据 new_workbook = app.books.add() #新建工作簿 new_worksheet = new_workbook.sheets.add(sheet_name) # 在新建工作簿中新增名为“产品销售统计”的工作表 new_worksheet['A1'].value = header # 将要合并的工作表的列标题复制到新增工作表中 new_worksheet['A2'].value = all_data # 将要合并的工作表的数据复制到新增工作表中 new_worksheet.autofit() # 根据合并后的数据内容自动调整新增工作表的行高和列宽 new_workbook.save('d:\\table\\上半年产品销售统计表.xlsx') # 保存新建工作簿并命名为“上半年产品销售统计表.xlsx" app.quit()知识延伸 第7行代码中 的None是python中的一个常量,表示一个空对象,它有自己的数据类型NoneType。需要注意的是,Non和一些为空的对象,如空列表([])、空字符串('')等是不一样的。 第24行代码中的autofit()是xlwings模块中工作表对象的函数,用于自动适应调整整个工作表的列宽和行高。 语法格式: autofit(axis=None) 参数:axis=None,若省略,表示同时自动适应调整列宽和行高;若设置为’rows‘或’r',表示自动适应调整行高;若设置为‘columns’或‘c',表示自动适应调整列宽 将工作簿中名称有规律的工作表合并到一个工作表——采购表 import os import xlwings as xw workbook_name = 'd:\\table\\采购表.xlsx' # 指定要合并工作表的工作簿 sheet_names = [str(sheet)+'月' for sheet in range(1,7)] # 列出工作簿中要合并的有规律的工作表名称 new_sheet_name = '上半年统计表' # 指定要合并后的新工作表名称 app = xw.App(visible = False, add_book = False) workbook = app.books.open(workbook_name) for i in workbook.sheets: if new_sheet_name in i.name: #判断工作簿中是否已存在名为”上半年统计表“的工作表 i.delete() # 如果已存在,则删除该工作表 new_worksheet = workbook.sheets.add(new_sheet_name) # 在工作簿中新增一个名为”上半年统计表“的工作表 title_copyed = False for j in workbook.sheets: if j.name in sheet_names: if title_copyed == False: j['A1'].api.EntireRow.Copy(Destination = new_worksheet["A1"].api) # 将要合并的工作表的列标题复制到新增的工作表”上半年统计表中“ title_copyed = True row_num = new_worksheet['A1'].current_region.last_cell.row # 列出新增工作表含有数据的区域的最后一行 j['A1'].current_region.offset(1, 0).api.Copy(Destination = new_worksheet["A{}".format(row_num + 1)].api) #在最后一行的下一行复制其他要合并工作表的数据,不复制标题 new_worksheet.autofit() workbook.save() app.quit()使用python批量处理工作簿和工作表,这些案例中使用到的数据文件请点击这里https://download.csdn.net/download/weixin_48719464/87899612 |




【本文地址】
今日新闻 |
推荐新闻 |